AI Librarian
Using LLMs to organize all the things 🤖 📑📕📗📘

Contents
🌐 Why is the internet broken
🔧 Exploring some remedies (internet annealing)
🤖 LLMs as part of the solution (showing off my agent prototype)
📚 Proposing the commons librarian – using LLMs to strengthen the commons
Organizing stuff is laborious. That’s why my backpack as a teen looked like this:

Turns out the internet is actually very similarly chaotic as my backpack🤣.
Let’s look at Maggie Appleton’s internet topology illustration:

Each domain is lacking / fragmented / isolated in its own way. To prove that, let’s step through each domain working our way toward the center.

The dark forest of the internet (collective)

Search engines are just a crutch for the shortcomings of HTTP and DNS — without them you wouldn’t really be able to find things. I mean, what ways to keep things organized are there: domain names (DNS-protocol) and Hyper-Links? It’s bound to be messy.
The Urbit project puts it like this:
We think the internet can’t be saved. The way things are going, MEGACORP will always control our apps and services because we can no longer run them ourselves.
There have been some attempts like schema.org (created in 2011), to add some structure to the internet, but outside of annotating shop systems so that Google can index them more effectively I would not call them relevant for organizing the internet.
Also, it’s bound to get worse: LLMs🦙🦙 are entering the “dark forest“ 🌲🌲🦙🌲.

That might mean the state of the internet will go from fragmented to increasingly trashed & fragmented.
This “dark forest“ is the only truly global collective “web“ we have, but if it goes up in flames we still have many smaller spaces:
The Cozy Web (community)

The cozy web, as a sort of internet-undergrowth, offers small-scale coherence around many niches. It’s sad, though, that its pearls can’t organically propagate into a more collective dimension. 🤔
I struggle to keep up with all the telegram groups, discord servers and Facebook groups. It’s not like they make it easy to find things again 🤷. If you really care, you’ll have to get organized.
Fine — I’ll organize it myself 💦 (Individual)
How do you keep track of all the links, articles, videos and papers?
Maybe you don’t. Your parents probably use browser bookmarks. 😉
Have you tried digital gardening 💦 or building a second brain 💦 e.g., using Roam, Tana, Obsidian, Zettelkasten, Evernote, Memex etc.
Main disadvantage here is that if you want good results, you have to come to terms with the fact that organizing stuff is a lot of work.
Internet Annealing
After learning about neural annealing from a talk by the Qualia Research Institute about neural annealing i have come to really appreciate the term, borrowed originally from metal works:
Annealing involves heating a metal above its recrystallization temperature, keeping it there for long enough for the microstructure of the metal to reach equilibrium, then slowly cooling it down, letting new patterns crystallize.
It’s going from a dissonant / fragmented structure to a more coherent one — the process of crystallizing a more useful structure.
In the case of “neural annealing” it would describe how the brain “smooths out“ / mends dissonances / trauma.
In case of the internet that would mean creating a structure that:
is more organized, more navigable and discoverable
is not prone to misinformation, abuse and scams
is so inclusive it can host contradictions
The same kind of annealing could be wished upon any mind, library, family, community or society. 😜
As the internet is so rich in information but lacking in structure, there is lots of annealing to do — divides between individual, community and collective silos to bridge, bones to be added into the blob.
Future internet substrate candidates
The HTTP-hyperlinked internet won’t disappear anytime soon. That does not mean that the technology to save the day hasn't already been in development for a decade 🎉.
The closest tech to “what the internet is missing“, that I know is Ceptr with its goal to enable a Global Nervous System. Ceptr would, in part, be built on top of the more well known Holochain with its distributed apps (dApps).
Holochain is a distant relative of blockchains such as Ethereum that are used to build Decentralized Autonomous Organizations which themselves make a good candidate for being part of an internet substrate with their programmable smart-contracts just waiting to be put to use for something actually useful. 😈
Ceptr and related candidates such as the Ad4m-Protocol or MAP each allow for a reliable yet much more expressive substrate. For example, HTTP, the currently dominant internet protocol only has a notion of client and server - request and response without any notions of authorship, third parties, social ontology, value creation or whatever notions may be required for an internet that would serve the world tomorrow. It’s not that these notions need to be present per se, but that a sufficiently expressive substrate would not shut the door on them preemptively.
Maybe the future internet needs protocols for economic-organizational expression or might include ways of modeling distributed economic activities.
LLM librarian prototype
Annealing the internet is a big ask — let’s step back and look at the humble prototype that prompted me to write all this:
It was created at the RE:Place Academy Voyage 2024 (a kind of hackerthon) in North Wales at the Astrals Ship organized by Prisma Events.

We explored how LLMs could act as digital librarians, which, given a specific schema, would materialize and update a schema-compliant library (dataset).
We let our prototype librarian agent loose in the realm of an Obsidian vault — our poor man’s graph database.
Starting with a simple schema: collecting parent-child relationships:

Our librarian, given the following text:
Leto Atreides, 45 is the father of Paul Atreides
Paul turned 22 2 years ago.
would then produce:
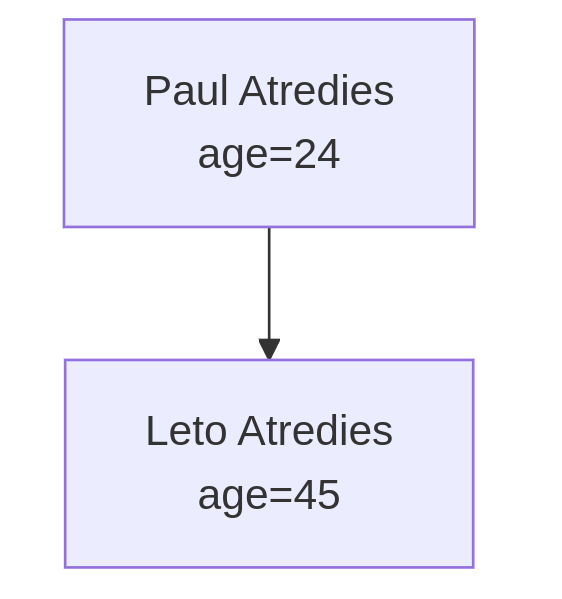
You can see the whole LLM interaction terminal log for this particular input here if want to peek under the hood. Below you will also find the proposed architecture that we used with the purple nodes being the ones actually focused on most during the couple days of prototyping.

While we fed it only small chunks of text, the goal would, of course, be to ingest increasingly diverse content from various sources like websites and APIs.
Personal AI Librarian (individual)
What kind of structures would you like to see crystallized? What do you study or deeply investigate?
I would love to see more specialized search engines — doing much more narrow crawling but with much higher quality schema and processing behind them.

Mario Yanez, who participated in the voyage, was interested in connecting eco-villages as well as regional movements.
Steve Ballmer, who didn’t participate 😉, created usafacts.org.
Cozy web librarian & commons librarian

Technical challenges aside — how does one maintain a community, country or world-spanning structure like a knowledge graph? We explored in the beginning the dark forest of the internet and how it doesn’t have a way of annealing itself, because the internet substrate is lacking in it’s current form.
Nobody has really tried, AFAIK, such a consolidation of well-structured, individually sourced graph data and brought it into an actually useful superstructure of some kind.
Initially things won’t line up — will be fragmented but there are ways of going from fragmentation to fragmentation-awareness to fragmentation-integration.

A democratic approach comes to mind; various ways to model ownership. There are lower and higher forms to approach this — some that we have not yet achieved collectively in human history. Let’s just call this process “commoning” — a gradual interweaving of the personal graph structures (“library”) with first communal ones and eventually collective dimensions. “Commoning” is similar to “publishing“ but more implicit.
Tools like software and AI can help to digitally manifest and maintain these structures — including via annealing:

(src: Simulated annealing)
This type of internet and social consolidation, or annealing, cannot be magically done by AI for us. AI should never act as an oracle but as a tool, with humans steering — setting the perimeter, refining the schema, correcting mistakes.
AI librarians will have to make decisions, but we shouldn’t tell them “to put the good books on the left stack and the bad ones on the right” — that would be oracle-type usage. That’s why we build the librarian prototype with a very narrow schema (pretty much an SQL ERD).
We do want piles of good books though — that could be facilitated by democratic processes or an internet substrate enabling even higher possibilities.
It’s coming anyway: AIs with graphs 🕸️🤖🕸️
I just co-built a little personal librarian in mid-2024 but every month the tooling to build this stuff gets more powerful and cheaper:
tool use: LLMs using search engines — a no brainer
agents: allowing more complex knowledge retrieval e.g. traversal of structures like websites or file systems
RAG: using a novel structure to inform the LLMs about relevant context
Microsoft GraphRAG — “creating a graph and then using it during retrieval”
documind — schema based extraction from documents
graphiti — modeling temporal relationships of entities over time
Most likely, this list is outdated already.
I am curious about how smart contract or dApp mediated AI agent interactions will look like. We won’t be using them if they are not useful.
Lots of annealing ahead. Anneal all the things!

Thanks for reading 🙂🙏